As the title suggests, I am going to publish a series of blog posts discussing and demonstrating different attack vectors against LLMs. This is the first post of the series that deals with the 101s; it talks about:
- The formula
- The black box
- The error
Let’s get started.
LLM or Large Language Model is basically a Machine Learning model that’s based on transformer. Transformer is a special Neural Network architecture and its idea was proposed by Google Brain team(Google) in 2017. It’s a primary feature (and function) of any LLM to understand and generate natural language(s) in the same way humans can do it. Before transformers, RNNs (Recurrent Neural Network) were used to perform language processing related tasks, but it has certain drawbacks because of which they were discarded:
- Slow
- Hard to train
- Inefficient
Let’s try to understand aforesaid drawbacks using an example. Suppose there’s a program that solely uses RNN to translate input sequences(sentences). Now, because of how RNN works, the program will only be able to process and translate a single element/word of the given input sequence at a time, making the whole translation task time consuming. And that’s also one of the reasons why it is hard to train RNN model(s); it can only focus on a single element at a time. Even parallelization using GPUs wont solve this problem because of the very nature of RNN: each computational cell in RNN is connected to the previous one and it relies on its output for further processing.
Also, RNNs face this issue called vanishing gradient when working with long sequences. So, if we are working with a longer sentence, by the time it will reach the end of it, it won’t remember what was going in the beginning.
Transformer is equipped with following mechanisms that made it replace RNN for natural language understanding and generation related tasks:
Positional Encoding
Earlier, with RNNs, the information about the order of the words in the sequence was stored in the NN itself. With positional encoding, we now store the information about the order of word in a sequence in form of vector. Words in the sequence are converted into vectors(a list of numerical values that preserve the semantics) according to their context(Positional Embedding). The information about the order of the words/tokens in a sequence is now contained in the sequence itself, instead of storing it inside the NN, thus boosting up the performance of the model.
Self-Attention
Attention is a mechanism that is used in order to focus more on specific parts of the input sequence. Because of the training, the model knows what words it should be focusing more on, and accordingly, weights are assigned to each of the word in the sequence. Self-Attention is when the Attention is turned towards the input sequence completely, in order to develop greater understanding of words in context to other words in the sequence.
 Translation of input sequence (English to Hindi)
Translation of input sequence (English to Hindi)
Without self-attention, the translated text will lose some context and meaning.
The black box: how does it work
People think of LLMs as some higher intelligence, that when provided with a prompt (input text), it applies reasoning, calculations and algorithms to it in order to figure out the response/answer. Reality stands 10 miles away from where they’ve been wandering with their notions.
In abstraction, LLMs are nothing but super smart text completion programs that simply understand what the input sequence is trying to convey and then generate the permutation and combination of words that could best follow the input sequence.
The efficiency of an LLM depends upon its vocabulary size; the number of tokens that it uses. “What is a token?”, well, token is a basic unit of text/code for LLM to understand/generate language, a token can be anything from a character, a subword, or even a word; it all depends upon tokenization method being used.
Any LLM is pre-equipped with a huge list of tokens, so as to when a prompt comes in, it calculates the probability distribution of the next token that could best follow the input sequence; what are the best chances that a particular word or a combination of word can be part of the input prompt.
The output generated(in the backend) is made up of two things:
- Tokens
- Probability
Assuming that each word in the sequence will be considered as a token, following image envisages what the generated output might look like:
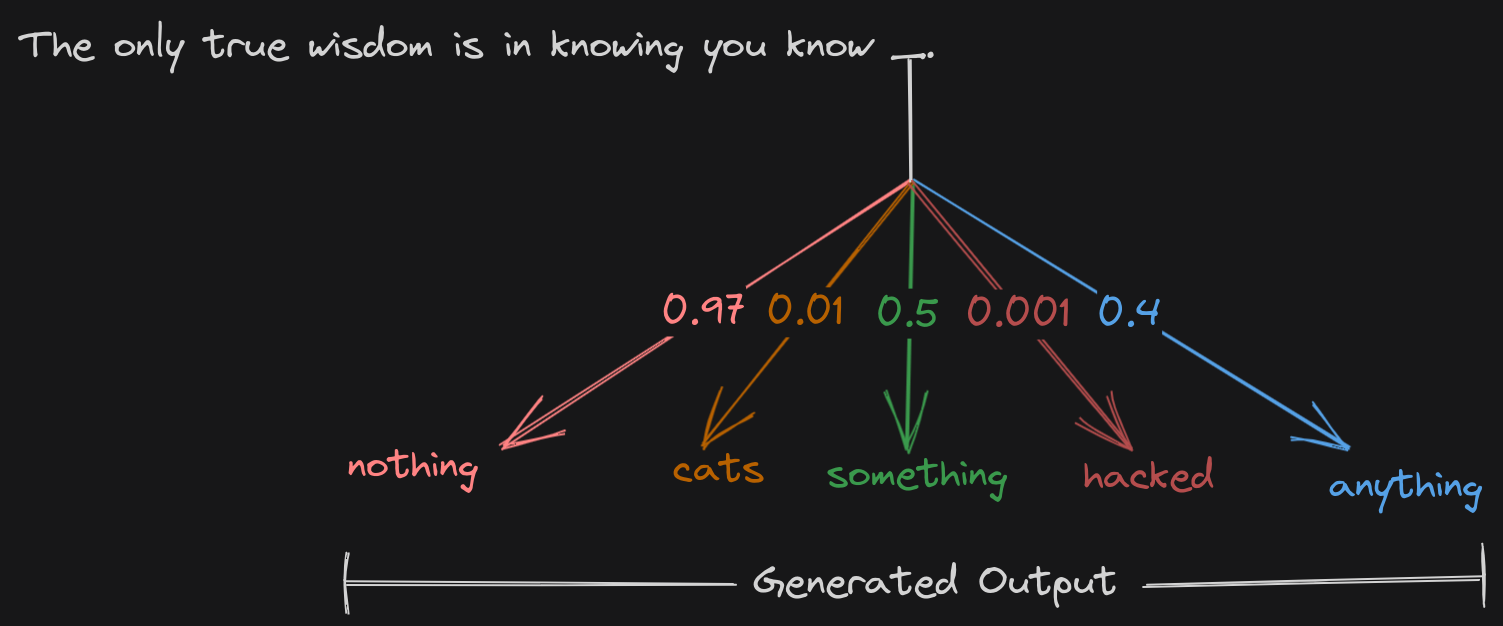
Now, depending upon certain parameters, token will be selected and returned to the user as the final output. Following are some of those parameters:
- Temperature: A parameter that can be used to control the creative aspect of the transformer. If set high, it will be selecting such tokens that have a high chances(probability value) of following a particular sequence/statement.
- Top-k: A parameter that selects top-k token(s) from the generated list of tokens, sorted in the order of increasing to decreasing probability, k’s value can be provided by the user.
- Top-p: A parameter that selects token(s) based upon the sum of probability from the generated list of tokens.
You can tinker around with these parameters in Open AI Playground
The error: where does it lack
LLMs are very capable of generating analytical and fluent as well as diverse and creative texts. But, there are places/situations where it has been known/seen to have generated output(s), while exercising its creative freedom, that completely deviate from facts and/or contextual logic.
LLMs are trained on general knowledge, so if you ask it about something specific such as opening and closing hours of a particular restaurant, it will give you a generic/generalized answer instead of a specific one. Your favourite restaurant might be opening at 11 A.M. but the LLM might say that it’s 8 A.M. Answers are provided on the basis of extensive training data (general knowledge) unlike chatbots, that contain specific information regarding a particular topic/entity. LLMs hallucinate.
Hallucination is basically when LLMs make stuff up, stuff that sounds authentic and plausible, but is nonsensical in its true form.
So now you know, that you can’t really trust the generated output 100%. The hallucination may result in slight inconsistencies in the output to completely fabricated texts that contradict the facts in hand. Following are some types of contradictions that you may encounter in the text(s) generated by an LLM:
- Sentence Contradiction: aka Self Contradiction; is when the generated output contradicts the output that was previously generated.
- Prompt Contradiction: aka Input Contradiction; is when LLM generates such text(s) that contradicts/deviates from the context that was specified in the input.
- Factual Contradiction: It is when the generated output contradicts some information that is objective in nature.
Here are some publicly available encounters of ChatGPT hallucinating:
That was all for this post. Meet you in the next one.
References
- Attention Is All You Need: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- LLM Parameters Demystified: Getting The Best Outputs from Language AI: https://txt.cohere.com/llm-parameters-best-outputs-language-ai/